# Launch 5 simulated experiments total_runs = 5 for run inrange(total_runs): # 🐝 1️⃣ Start a new run to track this script wandb.init( # Set the project where this run will be logged project="basic-intro", # We pass a run name (otherwise it’ll be randomly assigned, like sunshine-lollypop-10) name=f"experiment_{run}", # Track hyperparameters and run metadata config={ "learning_rate": 0.02, "architecture": "CNN", "dataset": "CIFAR-100", "epochs": 10, })
# This simple block simulates a training loop logging metrics epochs = 10 offset = random.random() / 5 for epoch inrange(2, epochs): acc = 1 - 2 ** -epoch - random.random() / epoch - offset loss = 2 ** -epoch + random.random() / epoch + offset
# 🐝 2️⃣ Log metrics from your script to W&B wandb.log({"acc": acc, "loss": loss})
defget_model(dropout): "A simple model" model = nn.Sequential(nn.Flatten(), nn.Linear(28*28, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(dropout), nn.Linear(256,10)).to(device) return model
defvalidate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0): "Compute performance of the model on the validation dataset and log a wandb.Table" model.eval() val_loss = 0. with torch.inference_mode(): correct = 0 for i, (images, labels) inenumerate(valid_dl): images, labels = images.to(device), labels.to(device)
# Log one batch of images to the dashboard, always same batch_idx. if i==batch_idx and log_images: log_image_table(images, predicted, labels, outputs.softmax(dim=1)) return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)
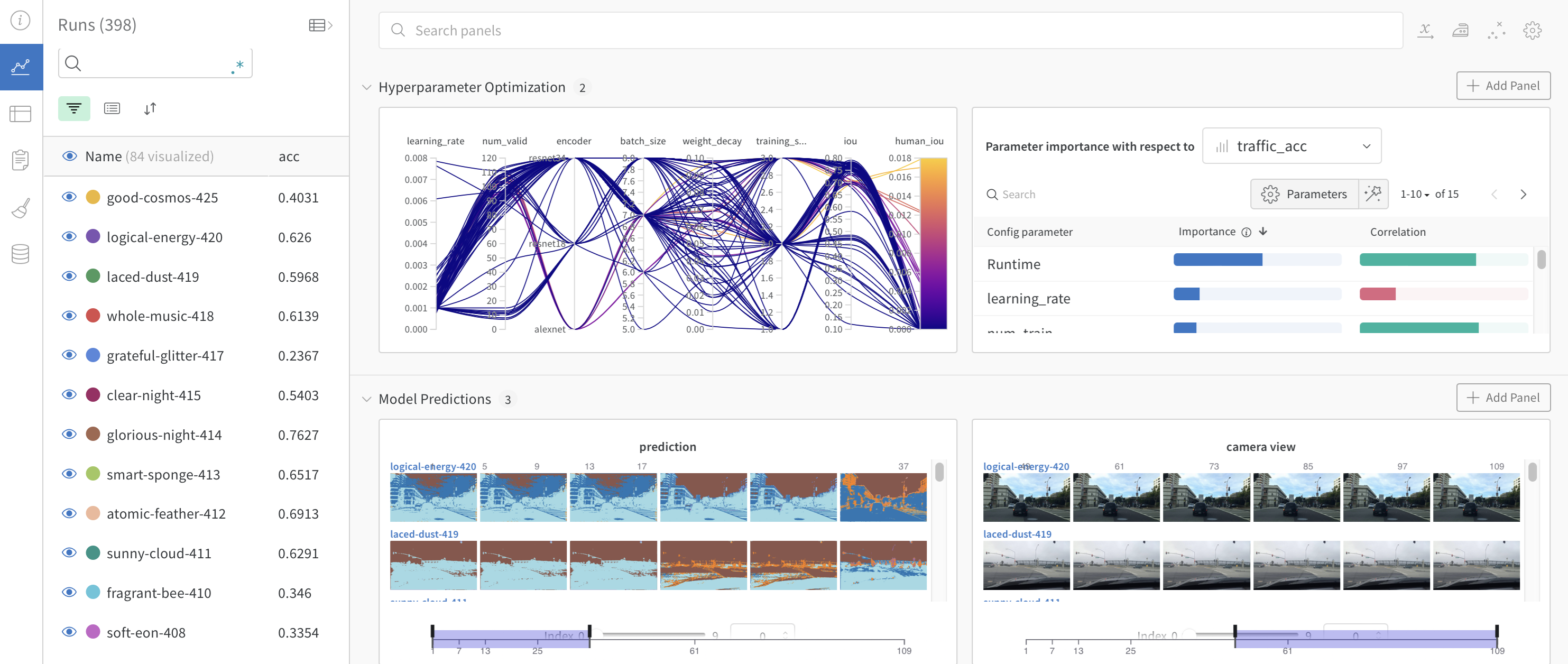
deflog_image_table(images, predicted, labels, probs): "Log a wandb.Table with (img, pred, target, scores)" # 🐝 Create a wandb Table to log images, labels and predictions to table = wandb.Table(columns=["image", "pred", "target"]+[f"score_{i}"for i inrange(10)]) for img, pred, targ, prob inzip(images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")): table.add_data(wandb.Image(img[0].numpy()*255), pred, targ, *prob.numpy()) wandb.log({"predictions_table":table}, commit=False)
# Start a wandb run wandb.init(project="pytorch-intro")
# Simulating a model training loop acc_threshold = 0.3 for training_step inrange(1000):
# Generate a random number for accuracy accuracy = round(random.random() + random.random(), 3) print(f'Accuracy is: {accuracy}, {acc_threshold}')
# 🐝 Log accuracy to wandb wandb.log({"Accuracy": accuracy})
# 🔔 If the accuracy is below the threshold, fire a W&B Alert and stop the run if accuracy <= acc_threshold: # 🐝 Send the wandb Alert wandb.alert( title='Low Accuracy', text=f'Accuracy {accuracy} at step {training_step} is below the acceptable theshold, {acc_threshold}', ) print('Alert triggered') break
# Mark the run as finished (useful in Jupyter notebooks) wandb.finish()
# Number of epochs to run # Each epoch includes a training step and a test step, so this sets # the number of tables of test predictions to log EPOCHS = 1
# Number of batches to log from the test data for each test step # (default set low to simplify demo) NUM_BATCHES_TO_LOG = 10#79
# Number of images to log per test batch # (default set low to simplify demo) NUM_IMAGES_PER_BATCH = 32#128
# training configuration and hyperparameters NUM_CLASSES = 10 BATCH_SIZE = 32 LEARNING_RATE = 0.001 L1_SIZE = 32 L2_SIZE = 64 # changing this may require changing the shape of adjacent layers CONV_KERNEL_SIZE = 5
defforward(self, x): # uncomment to see the shape of a given layer: #print("x: ", x.size()) out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
# define model, loss, and optimizer model = ConvNet(NUM_CLASSES).to(device) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
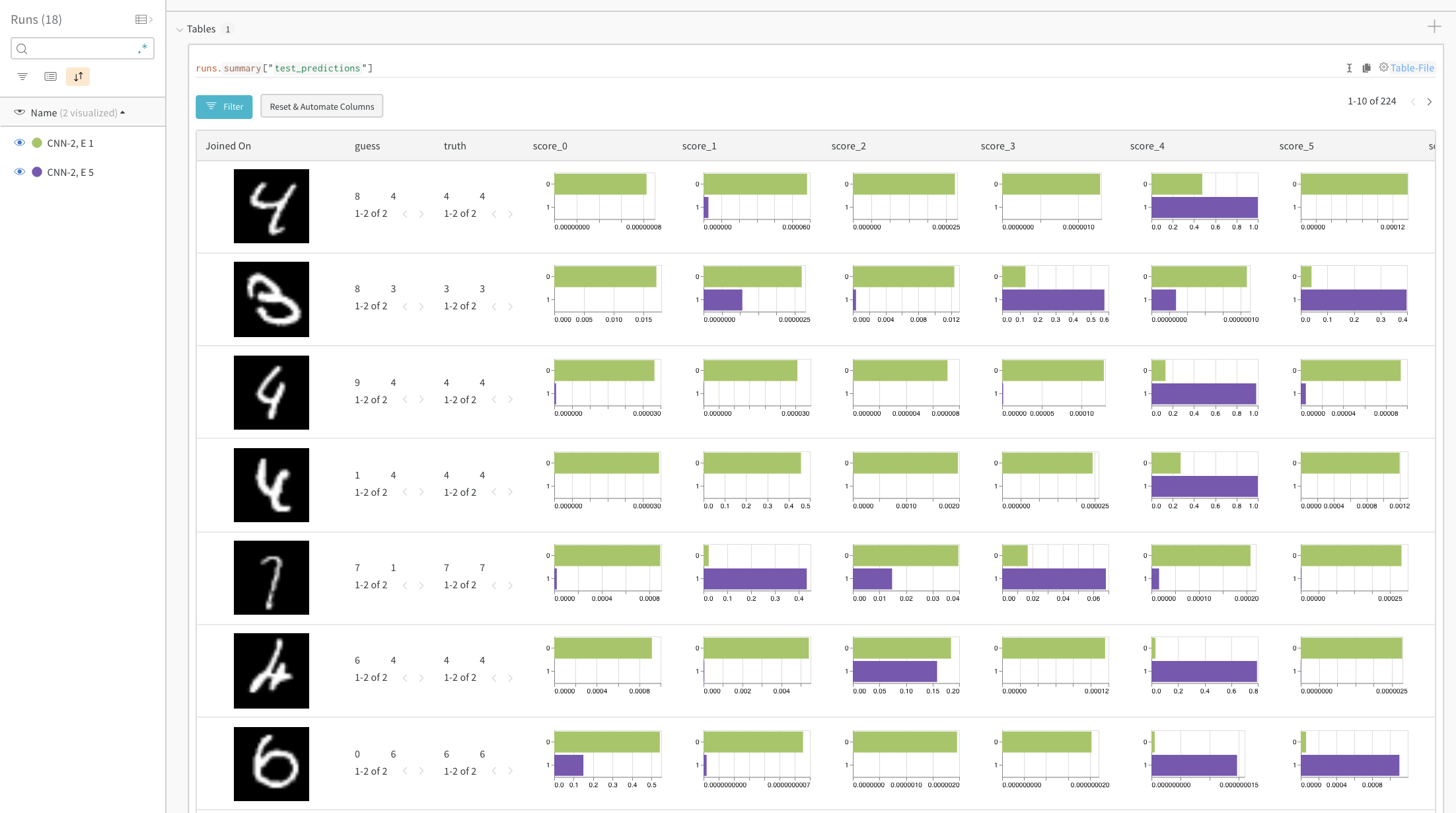
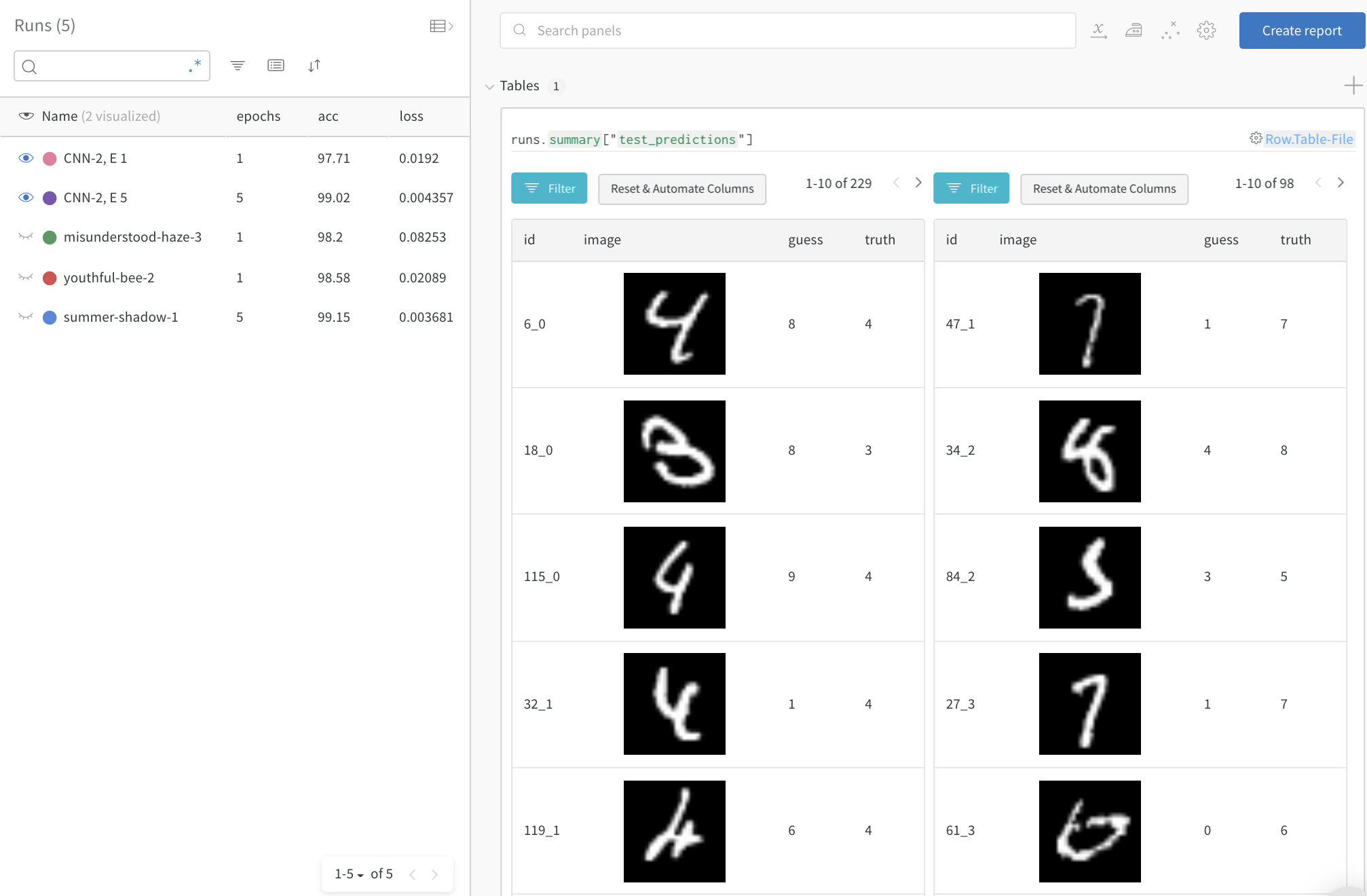
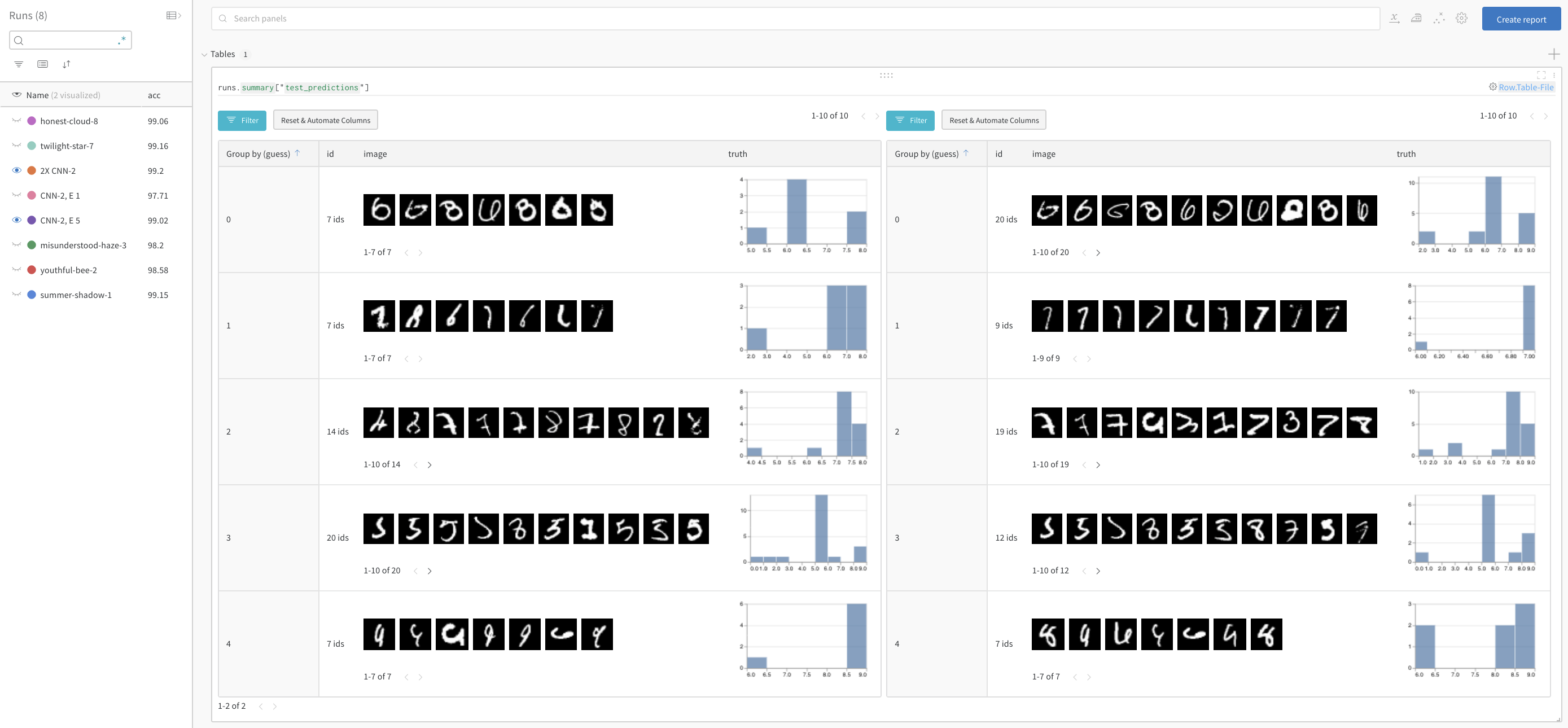
# convenience funtion to log predictions for a batch of test images deflog_test_predictions(images, labels, outputs, predicted, test_table, log_counter): # obtain confidence scores for all classes scores = F.softmax(outputs.data, dim=1) log_scores = scores.cpu().numpy() log_images = images.cpu().numpy() log_labels = labels.cpu().numpy() log_preds = predicted.cpu().numpy() # adding ids based on the order of the images _id = 0 for i, l, p, s inzip(log_images, log_labels, log_preds, log_scores): # add required info to data table: # id, image pixels, model's guess, true label, scores for all classes img_id = str(_id) + "_" + str(log_counter) test_table.add_data(img_id, wandb.Image(i), p, l, *s) _id += 1 if _id == NUM_IMAGES_PER_BATCH: break
# train the model total_step = len(train_loader) for epoch inrange(EPOCHS): # training step for i, (images, labels) inenumerate(train_loader): images = images.to(device) labels = labels.to(device) # forward pass outputs = model(images) loss = criterion(outputs, labels) # backward and optimize optimizer.zero_grad() loss.backward() optimizer.step()
# ✨ W&B: Log loss over training steps, visualized in the UI live wandb.log({"loss" : loss}) if (i+1) % 100 == 0: print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, EPOCHS, i+1, total_step, loss.item()))
# ✨ W&B: Create a Table to store predictions for each test step columns=["id", "image", "guess", "truth"] for digit inrange(10): columns.append("score_" + str(digit)) test_table = wandb.Table(columns=columns)
# test the model model.eval() log_counter = 0 with torch.no_grad(): correct = 0 total = 0 for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) if log_counter < NUM_BATCHES_TO_LOG: log_test_predictions(images, labels, outputs, predicted, test_table, log_counter) log_counter += 1 total += labels.size(0) correct += (predicted == labels).sum().item()
acc = 100 * correct / total # ✨ W&B: Log accuracy across training epochs, to visualize in the UI wandb.log({"epoch" : epoch, "acc" : acc}) print('Test Accuracy of the model on the 10000 test images: {} %'.format(acc))
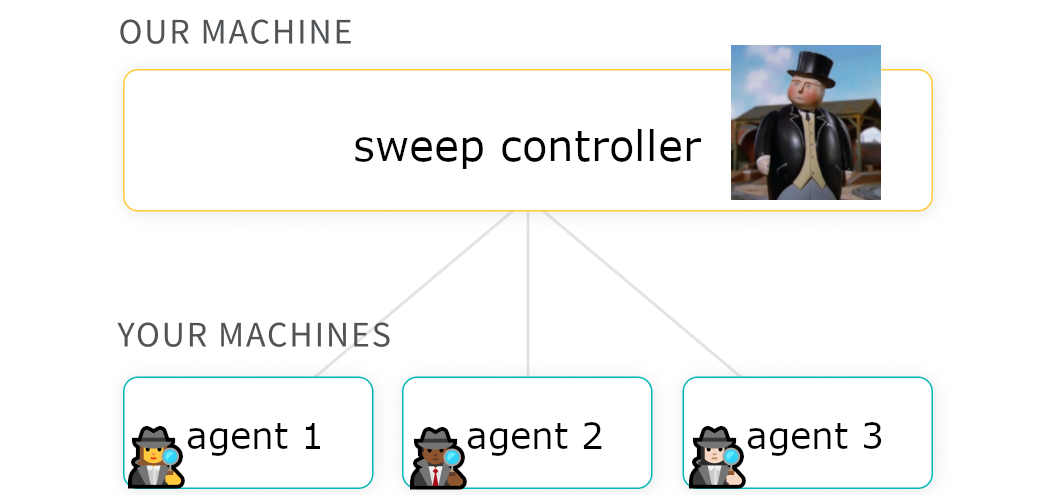
deftrain(config=None): # Initialize a new wandb run with wandb.init(config=config): # If called by wandb.agent, as below, # this config will be set by Sweep Controller config = wandb.config
# drop slow mirror from list of MNIST mirrors torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors ifnot mirror.startswith("http://yann.lecun.com")]
defload(train_size=50_000): """ # Load the data """
# the data, split between train and test sets train = torchvision.datasets.MNIST("./", train=True, download=True) test = torchvision.datasets.MNIST("./", train=False, download=True) (x_train, y_train), (x_test, y_test) = (train.data, train.targets), (test.data, test.targets)
# split off a validation set for hyperparameter tuning x_train, x_val = x_train[:train_size], x_train[train_size:] y_train, y_val = y_train[:train_size], y_train[train_size:]
# 🚀 start a run, with a type to label it and a project it can call home with wandb.init(project="artifacts-example", job_type="load-data") as run:
datasets = load() # separate code for loading the datasets names = ["training", "validation", "test"]
# 🏺 create our Artifact raw_data = wandb.Artifact( "mnist-raw", type="dataset", description="Raw MNIST dataset, split into train/val/test", metadata={"source": "torchvision.datasets.MNIST", "sizes": [len(dataset) for dataset in datasets]})
for name, data inzip(names, datasets): # 🐣 Store a new file in the artifact, and write something into its contents. with raw_data.new_file(name + ".pt", mode="wb") as file: x, y = data.tensors torch.save((x, y), file)
# ✍️ Save the artifact to W&B. run.log_artifact(raw_data)
# evaluate the model on the validation set at each epoch loss, accuracy = test(model, valid_loader) test_log(loss, accuracy, example_ct, epoch)
deftest(model, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.cross_entropy(output, target, reduction='sum') # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum()
# get the losses and predictions for each item in the dataset losses = None predictions = None with torch.no_grad(): for data, target in loader: data, target = data.to(device), target.to(device) output = model(data) loss = F.cross_entropy(output, target) pred = output.argmax(dim=1, keepdim=True)